O RabbitMQ é um software de mensageria de código aberto amplamente utilizado para a comunicação entre sistemas distribuídos. Ele implementa o padrão de mensageria AMQP (Advanced Message Queuing Protocol) e fornece uma plataforma robusta para troca de mensagens entre aplicativos e serviços.
Aqui estão alguns conceitos-chave relacionados ao RabbitMQ:
Mensagens: No RabbitMQ, as mensagens são unidades de informação que são enviadas e recebidas pelos diferentes componentes do sistema. Uma mensagem consiste em um payload (conteúdo) e opcionalmente em metadados adicionais, como cabeçalhos. As mensagens são enviadas para filas no RabbitMQ e, em seguida, consumidas pelos aplicativos interessados.
Produtor: Um produtor é um componente que envia mensagens para o RabbitMQ. Ele publica mensagens em uma fila ou em um tópico específico. Os produtores podem ser aplicativos ou serviços que geram mensagens para serem processadas ou compartilhadas com outros componentes.
Fila: Uma fila é uma estrutura de armazenamento no RabbitMQ que armazena as mensagens até que sejam consumidas pelos consumidores. As filas seguem o modelo “First-In, First-Out” (FIFO), ou seja, as mensagens são consumidas na ordem em que foram recebidas. Várias filas podem ser criadas no RabbitMQ para diferentes propósitos ou para separar diferentes fluxos de mensagens.
Consumidor: Um consumidor é um componente que recebe e processa as mensagens do RabbitMQ. Ele se inscreve em uma fila específica e, quando uma mensagem é disponibilizada na fila, o RabbitMQ a entrega ao consumidor para processamento. Os consumidores podem ser aplicativos ou serviços que executam ações com base nas mensagens recebidas.
Troca (Exchange): Uma troca é responsável por receber as mensagens dos produtores e roteá-las para as filas apropriadas no RabbitMQ. Ela recebe as mensagens de acordo com regras de roteamento definidas e decide qual fila receberá a mensagem. O RabbitMQ suporta diferentes tipos de trocas, como troca direta, de tópico, de cabeçalho e de fanout, permitindo diferentes padrões de roteamento.
Roteamento: O roteamento é o processo de enviar as mensagens do RabbitMQ das trocas para as filas corretas. Isso é feito com base em regras de roteamento que podem ser configuradas nas trocas. As regras de roteamento são definidas pelos produtores ao publicar as mensagens e podem ser baseadas em chaves de roteamento ou outros critérios definidos nas mensagens.
O RabbitMQ é amplamente utilizado para a comunicação assíncrona e o acoplamento fraco entre diferentes componentes de sistemas distribuídos. Ele fornece recursos avançados, como filas duráveis, confirmações de entrega, trocas personalizadas, roteamento flexível e suporte a vários padrões de troca de mensagens.
Ao usar o RabbitMQ, os desenvolvedores podem criar sistemas altamente escaláveis, resilientes e modularizados, onde os componentes podem se comunicar de forma eficiente e confiável por meio do envio e recebimento de mensagens.
Performance refere-se à capacidade de um sistema ou aplicativo executar suas tarefas de maneira eficiente e rápida, com o menor consumo possível de recursos, como CPU, memória e rede. Uma boa performance é essencial para proporcionar uma experiência de usuário satisfatória, garantir a eficiência operacional e lidar com cargas de trabalho crescentes.
Aqui estão algumas considerações e práticas para otimizar a performance de um sistema:
Análise e monitoramento: É importante realizar uma análise detalhada do sistema para identificar gargalos de desempenho. Isso pode envolver a medição do tempo de resposta, o monitoramento do uso de recursos e a identificação de áreas problemáticas. Ferramentas de monitoramento e profiling podem ajudar nessa análise.
Otimização de algoritmos: A eficiência dos algoritmos utilizados no sistema pode ter um impacto significativo na performance. É essencial escolher algoritmos eficientes e implementá-los de forma otimizada, levando em consideração as características específicas do problema a ser resolvido.
Cache: O uso de cache pode melhorar significativamente a performance, armazenando dados frequentemente acessados em memória para acesso rápido. Isso reduz a necessidade de buscar informações em locais mais lentos, como bancos de dados ou serviços externos.
Escalabilidade: Projetar o sistema para ser escalável é importante para lidar com um aumento na carga de trabalho. Isso pode envolver a distribuição da carga entre vários servidores, o uso de balanceamento de carga e a implementação de arquiteturas de microsserviços.
Otimização de banco de dados: Banco de dados é muitas vezes um componente crítico para a performance de um sistema. Otimizar consultas, criar índices apropriados e garantir um design eficiente do esquema do banco de dados pode melhorar significativamente o desempenho.
Paralelismo: Aproveitar o paralelismo e a concorrência pode acelerar a execução de tarefas. Isso pode ser alcançado por meio de threads, processos paralelos, programação assíncrona ou o uso de tecnologias específicas como o processamento em lote.
Profiling e tuning: A técnica de profiling envolve a coleta de dados de desempenho durante a execução do sistema para identificar gargalos e áreas de melhoria. Com base nos dados coletados, é possível ajustar e otimizar o sistema, seja ajustando parâmetros, redesenhando partes do código ou identificando problemas de alocação de recursos.
É importante lembrar que a otimização de performance é um processo contínuo e iterativo. À medida que o sistema evolui e as necessidades mudam, é necessário revisitar e refinar as estratégias de otimização. Monitorar regularmente a performance e realizar testes de carga também são práticas importantes para garantir que o sistema mantenha um bom desempenho ao longo do tempo.
Observabilidade é a capacidade de compreender e monitorar o comportamento interno de um sistema, especialmente em ambientes distribuídos e complexos. É uma prática importante no desenvolvimento de software e operações de sistemas para identificar e solucionar problemas, entender o desempenho e garantir a confiabilidade de um sistema em produção.
A observabilidade se baseia em três pilares principais:
Logs: Os logs são registros detalhados de eventos e atividades que ocorrem em um sistema. Eles fornecem informações úteis para rastrear e solucionar problemas, permitindo a análise de eventos passados e a identificação de padrões anormais. Os logs podem conter informações sobre erros, exceções, transações, tempo de resposta e outras métricas relevantes.
Métricas: As métricas são medidas quantitativas do desempenho e do estado de um sistema. Elas incluem informações como a taxa de transferência, a latência, a utilização de recursos e outras métricas específicas de um determinado sistema. As métricas são coletadas e armazenadas em intervalos regulares para permitir a análise de tendências e o monitoramento contínuo da saúde do sistema.
Rastreamento distribuído: O rastreamento distribuído envolve o monitoramento do fluxo de uma solicitação através de um sistema distribuído, permitindo identificar gargalos, atrasos e falhas de comunicação entre os diferentes componentes do sistema. Isso é especialmente útil em ambientes de microsserviços, onde várias partes do sistema podem estar interconectadas.
Além desses pilares, a observabilidade também pode envolver o uso de ferramentas e técnicas específicas, como telemetria, monitoramento de eventos, alertas e dashboards personalizados. O objetivo é obter uma visão abrangente do sistema em tempo real, permitindo que os desenvolvedores e operadores entendam o comportamento do sistema, identifiquem problemas e tomem medidas corretivas de forma proativa.
A observabilidade desempenha um papel importante no desenvolvimento e operação de sistemas modernos, especialmente em ambientes de nuvem e microsserviços. Ela ajuda a melhorar a resiliência, a escalabilidade e o desempenho do sistema, permitindo uma rápida detecção e solução de problemas. Ao investir na observabilidade, as equipes de desenvolvimento e operações podem melhorar a qualidade do software, a satisfação do usuário e a confiabilidade do sistema como um todo.
NoSQL, abreviação de “Not Only SQL”, é um termo utilizado para se referir a uma categoria de bancos de dados que diferem dos tradicionais bancos de dados relacionais (SQL). Esses bancos de dados NoSQL são projetados para lidar com grandes volumes de dados e oferecem uma abordagem flexível e escalável para o armazenamento e recuperação de informações.
Aqui estão algumas características e conceitos-chave relacionados aos bancos de dados NoSQL:
Modelagem flexível de dados: Os bancos de dados NoSQL permitem que você armazene dados sem um esquema fixo. Isso significa que você não precisa definir uma estrutura de tabela rígida antes de inserir dados. Em vez disso, você pode adicionar campos ou modificar a estrutura dos dados conforme necessário. Isso facilita a adaptação dos bancos de dados a cenários em que os requisitos de dados estão em constante evolução.
Escalabilidade horizontal: Os bancos de dados NoSQL são projetados para serem altamente escaláveis. Eles podem lidar com grandes volumes de dados e alto tráfego, distribuindo os dados em vários servidores. Isso é conhecido como escalabilidade horizontal, e permite que os bancos de dados NoSQL dimensionem de forma mais eficiente em comparação com os bancos de dados relacionais, que geralmente escalam verticalmente adicionando mais recursos a um único servidor.
Modelos de dados diversos: Os bancos de dados NoSQL oferecem diferentes modelos de dados para atender a diferentes necessidades. Alguns dos modelos de dados comuns são:
Banco de Dados de Documentos: Armazena os dados em documentos semelhantes a JSON.
Banco de Dados de Grafos: Modela as relações entre os dados por meio de nós e arestas.
Banco de Dados de Chave-Valor: Armazena os dados como pares de chave-valor.
Banco de Dados de Colunas Largas: Armazena os dados em colunas em vez de linhas, permitindo uma recuperação mais eficiente de subconjuntos específicos de dados.
Alta disponibilidade: Os bancos de dados NoSQL geralmente oferecem mecanismos para alta disponibilidade dos dados. Isso pode ser alcançado por meio de replicações, onde cópias dos dados são mantidas em vários servidores, garantindo que os dados estejam sempre disponíveis mesmo em caso de falhas.
Performance otimizada: Os bancos de dados NoSQL são projetados para oferecer alta performance em leitura e gravação de dados. Eles são otimizados para operações em grande escala e podem ser mais eficientes do que os bancos de dados relacionais em certos cenários.
Os bancos de dados NoSQL são amplamente utilizados em uma variedade de aplicativos, como aplicativos da web, análise de big data, processamento de dados em tempo real e aplicativos móveis. No entanto, é importante considerar cuidadosamente os requisitos e características do seu aplicativo antes de decidir usar um banco de dados NoSQL, pois eles podem exigir uma abordagem diferente em termos de modelagem de dados e consultas em comparação.
O MongoDB é um programa de banco de dados orientado a documentos, multiplataforma e de código aberto. Classificado como um programa de banco de dados NoSQL, o MongoDB utiliza documentos semelhantes a JSON com esquemas opcionais. Desenvolvido pela MongoDB Inc., é licenciado sob a Server Side Public License (SSPL), considerada não livre por várias distribuições e, ao mesmo tempo, membro da Aliança MACH.
A flexibilidade do MongoDB torna-se ideal para organizações de qualquer setor, auxiliando na remoção de barreiras à inovação. Para os desenvolvedores, é fácil e rápido trabalhar com essa ferramenta, o que permite dedicar mais tempo à criação de valor para o negócio em vez de focar na modelagem de dados. Além disso, o MongoDB Atlas, uma plataforma de dados de desenvolvedor na nuvem, facilita e acelera a construção de aplicações com dados em ambientes como AWS, Google Cloud e Microsoft Azure.
Para começar com o MongoDB, é possível utilizar uma linguagem de programação, API ou IDE, como a extensão do VS Code ou drivers específicos de linguagens como Python, Node.js e Java. O MongoDB Atlas também oferece uma interface web intuitiva para tarefas mais explicativas, garantindo uma experiência fluida e dinâmica para todos os interessados no universo dos bancos de dados NoSQL.
Instalação e Configuração no Windows
A instalação do MongoDB no Windows é um processo simples e direto. Vou te guiar através das etapas necessárias para instalar e configurar o MongoDB no seu computador com Windows.
Pré-Requisitos
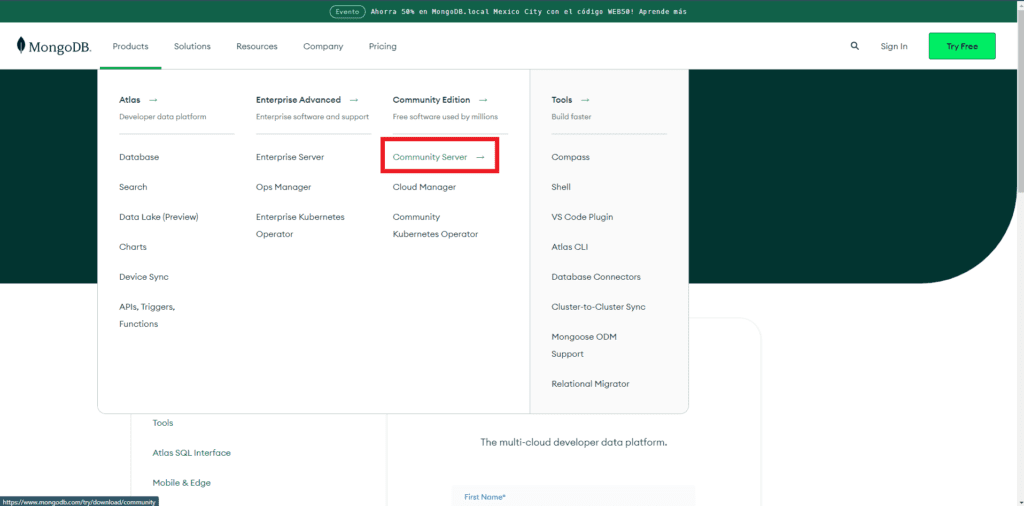
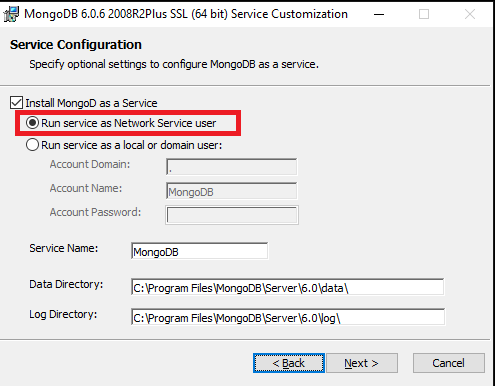
Antes de iniciar a instalação, você precisa baixar o arquivo de instalação do MongoDB. Para fazer isso, acesse a página oficial de downloads do MongoDB e escolha a versão adequada para o seu sistema operacional Windows. Faça o download e execute o instalador. Durante a instalação, certifique-se de que a opção “MongoDB como serviço” esteja selecionada, o que permitirá que o MongoDB seja configurado como um serviço do Windows.
MongoDB Community Server Download
Baixar e instalar MongoDB
MongoDB run service
Após a instalação
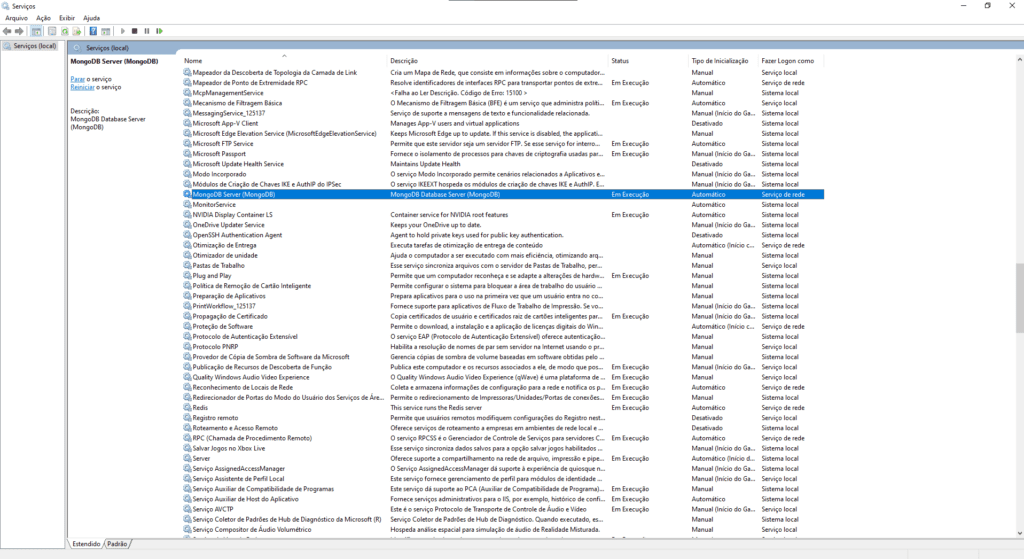
Você pode verificar se o serviço do MongoDB está em execução no Windows. Como na imagem abaixo:
MondoDB serviço em execução
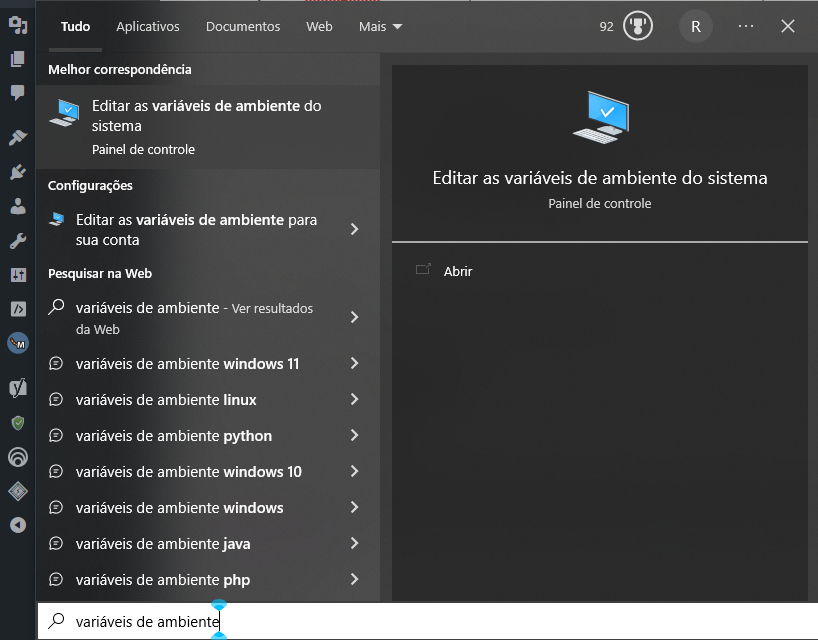
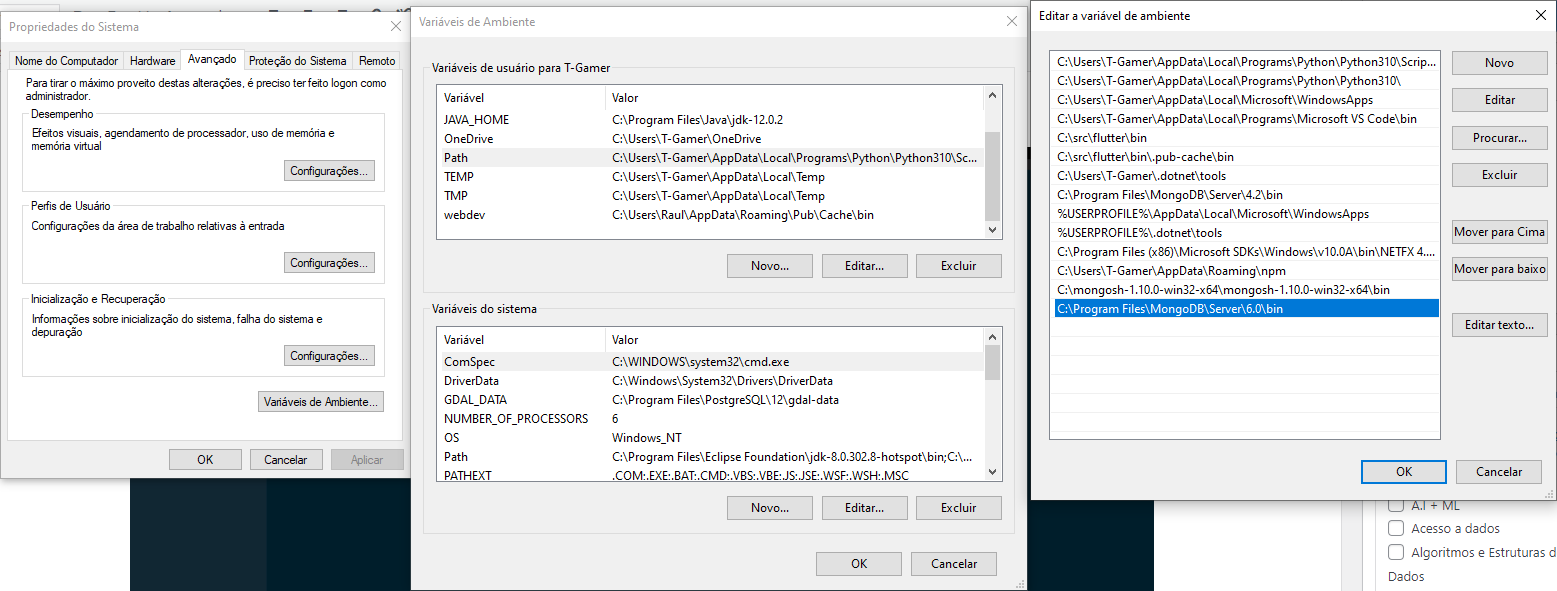
Agora vamos adicionar o binário mongod à sua variável de ambiente PATH do Windows.
Pesquisa na barra do Windows “variáveis de ambiente”:
Agora acrescente o caminho “C:\Program Files\MongoDB\Server\6.0\bin” no PATH do Windows.
Após a instalação, você precisará configurar o MongoDB como um cluster. Siga os passos abaixo:
Configuração de Cluster
Crie um diretório de dados e um arquivo de log:
Crie uma pasta chamada data no diretório raiz do seu disco rígido (C:\data\mongodb)
Dentro da pasta data, crie uma subpasta chamada db e outra chamada log
Configurar o caminho do banco de dados e do arquivo de log:
Abra o prompt de comando e digite o seguinte comando:
mongod –dbpath=C:\data\mongodb\db -logpath=C:\data\mongodb\db\log.txt -install
Inicializar o serviço do MongoDB:
Digite este comando no prompt:
net start MongoDB
Pronto! O seu cluster do MongoDB está configurado e funcionando. Agora você pode começar a utilizar o MongoDB no seu computador com Windows. Para acessar o MongoDB Shell (mongosh), siga as instruções de instalação do MongoDB Shell e desfrute dos recursos que o MongoDB oferece.
MongoDB Shell
MongoDB Shell é a maneira mais rápida de se conectar (e trabalhar com) MongoDB. Consulte dados, defina configurações e execute outras ações facilmente com esta interface de linha de comando moderna e extensível — repleta de realce de sintaxe, preenchimento automático inteligente, ajuda contextual e mensagens de erro.
Observação: o MongoDB Shell é um produto autônomo de software livre (Apache 2.0) desenvolvido separadamente do MongoDB Server.
Antes de iniciar a instalação, você precisa baixar o arquivo de instalação do MongoDB. Para fazer isso, acesse a página oficial de downloads do MongoDB Shell e escolha a versão adequada para o seu sistema operacional Windows. Faça o download e extraia os arquivos do arquivo baixado em C:\
Agora vamos adicionar o binário mongosh à sua variável de ambiente PATH do Windows.
Pesquisa na barra do Windows “variáveis de ambiente”:
Variáveis de ambiente
Agora acrescente o caminho “C:\mongosh-1.10.0-win32-x64\mongosh-1.10.0-win32-x64\bin” no PATH do Windows.
PATH Windows
Como teste abra o CMD e execute o comando mongosh –help
O MongoDB é um banco de dados orientado a documentos, o que significa que é diferente dos bancos de dados tradicionais que seguem o modelo relacional. Eu gosto de trabalhar com MongoDB porque ele é flexível e permite que várias fontes e terceiros se conectem diretamente a ele. Além disso, ele pode ser integrado a diferentes aplicações usando conectores disponíveis.
Coleções
As coleções no MongoDB são grupos de documentos e funcionam de forma semelhante às tabelas em bancos de dados relacionais. As coleções são úteis para agrupar documentos relacionados entre si, facilitando a gestão e consulta dos dados. Além disso, a estrutura das coleções em MongoDB permite armazenar documentos com estruturas diferentes dentro de uma mesma coleção, garantindo maior flexibilidade.
Documentos
Os documentos são os registros em um banco de dados orientado a documentos, como o MongoDB. Os documentos são armazenados no formato BSON, que é uma representação binária do JSON. Achei interessante que no MongoDB, os documentos podem conter campos variáveis, fazendo com que cada documento seja único e independente. Isso facilita a manipulação de dados e permite criar soluções mais eficientes para diferentes situações.
Modelagem de Dados
A modelagem de dados no MongoDB é uma etapa importante para garantir que o banco de dados seja eficiente e fácil de manter. Vou abordar dois tipos principais de modelagem no MongoDB: Embutida e Referenciada.
Embutida
A modelagem embutida é quando incorporamos todos os dados relacionados em um único documento. Essa abordagem é útil para melhorar o desempenho de leitura, já que todas as informações necessárias estão no mesmo local. Além disso, é possível trabalhar com estruturas de dados complexas, como matrizes e geoespaciais. Por exemplo, considere um blog com postagens e comentários:
{
"titulo": "Postagem do Blog",
"conteudo": "Este é o texto do conteúdo do blog",
"autor": "José da Silva",
"data_publicacao": "2023-06-19",
"comentarios": [
{
"autor": "Maria",
"texto": "Ótima postagem!",
"data": "2023-06-19"
},
{
"autor": "Pedro",
"texto": "Muito interessante",
"data": "2023-06-20"
}
]
}
Neste exemplo, os comentários estão embutidos no documento da postagem do blog. Isso facilita a consulta de postagens e seus respectivos comentários.
Referenciada
A modelagem referenciada consiste em criar referências entre documentos, o que nos permite separar informações e buscar dados mais específicos. Essa abordagem é útil quando temos dados que não precisam ser consultados sempre ou quando queremos evitar redundâncias e facilitar a manutenção dos dados. Por exemplo, usando o mesmo caso do blog, teríamos documentos separados para postagens e comentários:
Postagem:
{
"_id": ObjectId("60cc45821342abcd1234"),
"titulo": "Postagem do Blog",
"conteudo": "Este é o texto do conteúdo do blog",
"autor": "José da Silva",
"data_publicacao": "2023-06-19"
}
Aqui, os comentários têm uma referência para a postagem relacionada, permitindo consultas mais específicas e uma organização mais fácil.
Índices e Otimização
Neste artigo, abordarei os índices no MongoDB e como otimizar as consultas usando-os.
Criação de Índices
Criar índices no MongoDB é essencial para melhorar a performance das consultas. Eles são estruturas de dados adicionais que armazenam parte do conjunto de dados da coleção em uma forma fácil de percorrer, ordenada pelo valor do campo especificado. Os índices ajudam a acelerar pesquisas e operações baseadas em intervalos, produzindo resultados de consultas mais rápidos e eficientes. Além disso, podem ser criados e removidos conforme necessário para se adaptar às mudanças nos requisitos e padrões de consulta do aplicativo1.
Para criar um índice no MongoDB, primeiramente, é preciso identificar os campos mais comuns nas consultas e declarar índices nesses campos. Se, por exemplo, minha aplicação consulta frequentemente por “nome” e “idade”, criar índices nesses campos ajudará na velocidade das consultas. Os índices compostos2 também podem ser criados, combinando mais de um campo. É importante ter em mente que criar muitos índices desnecessários pode causar lentidão.
Otimização de Consultas
Otimizar consultas no MongoDB envolve o uso eficiente de índices e projeções3. A utilização dos índices corretos possibilita a recuperação rápida das informações desejadas e evita a lentidão causada por operações de varredura da coleção inteira.
Para garantir que os índices sejam utilizados nas consultas, podemos utilizar a função explain no MongoDB. Essa função fornece informações detalhadas sobre o plano de execução da consulta e indica se os índices foram utilizados ou não.
Além disso, a seleção e o ordenamento corretos dos campos nos índices compostos são essenciais para uma performance eficiente. A ordem dos campos em um índice composto afeta diretamente a forma como o MongoDB utiliza o índice.
Em suma, a criação e a utilização corretas dos índices são de extrema importância para a otimização das consultas no MongoDB. Planejar cuidadosamente os índices necessários, baseados nos padrões de consulta de cada aplicação, é essencial para garantir uma boa performance e evitar a lentidão no banco de dados.
A autenticação é uma parte importante da segurança do MongoDB. Por padrão, o MongoDB não possui autenticação ativada, o que significa que qualquer usuário com acesso ao servidor onde o banco de dados está instalado pode adicionar e excluir dados. Para resolver isso, é importante habilitar a autenticação e garantir que apenas usuários autorizados possam acessar os dados. Existem várias formas de autenticação disponíveis no MongoDB, incluindo a autenticação baseada em senhas e a autenticação usando certificados X.509.
Autorização
Após ter a autenticação ativada, o próximo passo é garantir que os usuários autorizados tenham permissões adequadas para acessar e modificar os dados. Para isso, o MongoDB possui um sistema de controle de acesso baseado em funções, que permite atribuir diferentes funções aos usuários, dependendo das suas necessidades. Essas funções controlam as ações que os usuários podem executar no banco de dados. Além disso, é possível criar funções personalizadas para atender aos requisitos específicos da sua aplicação.
Encriptação
A encriptação é outra camada de segurança essencial para manter seus dados protegidos. O MongoDB suporta a encriptação tanto em trânsito quanto em repouso. A encriptação em trânsito utiliza TLS/SSL para proteger os dados enquanto eles são transmitidos entre o cliente e o servidor. A encriptação em repouso garante que os dados armazenados no disco sejam protegidos usando a encriptação WiredTiger, que é o mecanismo de armazenamento padrão do MongoDB.
Ao seguir essas práticas recomendadas para autenticação, autorização e encriptação, posso garantir que os dados armazenados no MongoDB estarão mais protegidos e seguros.
Backup e Restauração
Ferramentas de Backup
No MongoDB, o backup e a restauração de dados são atividades muito importantes para garantir a segurança e integridade de nossos bancos de dados. Para realizar o backup, utilizo a ferramenta mongodump, que cria um backup do banco de dados no formato BSON. O processo do backup pode ser realizado para todo o servidor, para um banco de dados específico ou até mesmo para uma coleção específica 1.
Geralmente, ao executar o mongodump, o arquivo BSON gerado é compactado e armazenado no diretório dump/. No entanto, é possível configurar o mongodump para salvar o arquivo BSON em um local personalizado. Além disso, devemos ter em mente que é possível utilizar filtros e consultas durante o processo de backup para selecionar apenas os dados que desejamos salvar.
Procedimentos de Restauração
A restauração dos dados do backup no MongoDB é feita através do comando mongorestore. A ferramenta mongorestore é responsável por ler os arquivos BSON gerados pelo mongodump e restaurar as informações no banco de dados 1.
É importante ressaltar que durante o processo de restauração, a criação de índices ocorre após a restauração dos dados. Dessa forma, evitamos possíveis problemas com a integridade dos dados. Além disso, para garantir um processo de restauração seguro, devemos sempre verificar se a versão do MongoDB no servidor é compatível com os arquivos BSON que estamos tentando restaurar.
Ao executar o mongorestore, podemos especificar o local onde os arquivos BSON estão armazenados. Assim, o comando irá restaurar os dados para o banco de dados adequado. Caso necessário, também podemos utilizar os recursos de consulta e filtro disponíveis no mongorestore. Isso nos permite escolher quais dados serão restaurados ou até mesmo ajustar as informações durante o processo de restauração.
Ao seguir essas etapas e utilizar as ferramentas adequadas, consigo garantir a segurança dos meus dados no MongoDB e realizar um processo de backup e restauração eficiente e confiável.
Monitoramento
Ferramentas de Monitoramento
No ambiente do MongoDB, as ferramentas de monitoramento são essenciais para garantir o bom desempenho e a estabilidade do banco de dados. O próprio MongoDB possui recursos e utilitários para monitoramento, como o db.enableFreeMonitoring(), que oferece monitoramento gratuito na nuvem para instâncias individuais ou conjuntos de réplicas.
Outras ferramentas disponíveis estão listadas na seção recursos mencionada anteriormente e podem ajudar a manter o controle sobre as instâncias e otimizar os planos de manutenção.
Algumas ferramentas de monitoramento populares são:
ClusterControl
MongoDB Management Service (MMS)
Site24x7
Métricas
Monitorar as métricas do MongoDB é fundamental para entender a capacidade do seu banco de dados e observar a utilização dos recursos. Além disso, é possível identificar comportamentos anormais e problemas de desempenho.
Algumas métricas importantes incluem:
Operações de leitura e escrita por segundo
Latência nas operações de leitura e escrita
Taxa de retorno de consultas
Uso de memória
Eu sempre enfatizo a importância de acompanhar essas métricas regularmente, pois isso permite detectar e reagir a problemas em tempo real e melhorar o desempenho geral do banco de dados e das aplicações relacionadas. Além disso, isso ajuda a garantir a conformidade com os acordos de nível de serviço (SLAs) e requisitos de proteção e governança de dados.
Para um entendimento mais aprofundado das métricas, recomendo a leitura do artigo onde são abordados os principais aspectos do monitoramento do MongoDB e as métricas relevantes.
Desempenho
Tuning
Quando se trata de melhorar o desempenho do MongoDB, é essencial realizar ajustes para garantir que o banco de dados funcione de maneira eficiente. Uma das áreas que podem afetar significativamente o desempenho é o bloqueio nas transações. O MongoDB usa um sistema de travamento para garantir a consistência do conjunto de dados. Se certas operações forem demoradas ou uma fila se formar, o desempenho será degradado à medida que as solicitações e operações esperam pelo bloqueio1. Eu recomendaria monitorar e ajustar regularmente o desempenho do MongoDB nessa área.
Outro aspecto fundamental para o ajuste de desempenho é a otimização de consultas. Devemos garantir que as consultas ad hoc, a indexação e a agregação em tempo real estejam funcionando de maneira eficaz para aproveitar ao máximo o desempenho do MongoDB.
Dimensionamento
O MongoDB é uma base de dados distribuída por padrão e oferece uma capacidade de dimensionamento horizontal extensa sem necessidade de alterações na lógica do aplicativo2. Isso permite lidar com o crescimento dos dados e a demanda de maneira mais eficiente.
Além disso, podemos segmentar e replicar dados usando clusters de fragmentos e conjuntos de réplicas, respectivamente. Isso ajudará a melhorar ainda mais o desempenho e a disponibilidade dos sistemas baseados em MongoDB.
É fundamental escolher a estratégia de dimensionamento adequada para seu caso de uso específico, levando em conta os requisitos de performance, espaço em disco e redundância de dados. Consideremos cuidadosamente as opções de fragmentação e replicação para garantir a melhor solução para nossas necessidades.
Em resumo, o desempenho e o dimensionamento são aspectos críticos para garantir a eficiência e a escalabilidade do MongoDB. Ao monitorar e ajustar regularmente o desempenho do sistema e selecionar a estratégia de dimensionamento correta, eu posso garantir um bom funcionamento do meu banco de dados MongoDB.
Microsserviços é uma abordagem arquitetural para o desenvolvimento de sistemas de software, onde um aplicativo é dividido em pequenos serviços independentes e autônomos, cada um responsável por uma função específica do sistema. Cada microsserviço é implementado, implantado e escalado de forma independente, e pode ser desenvolvido em diferentes linguagens de programação e tecnologias, conforme adequado.
Aqui estão alguns conceitos e características relacionados aos microsserviços:
Desacoplamento: Os microsserviços são projetados para serem independentes um do outro. Cada serviço é responsável por uma única funcionalidade bem definida e não depende dos detalhes internos dos outros serviços. Isso permite que cada serviço seja desenvolvido, testado e implantado separadamente, facilitando a evolução e manutenção do sistema.
Escalabilidade: Cada microsserviço pode ser dimensionado independentemente de acordo com a demanda específica. Isso permite que os recursos sejam alocados de forma mais eficiente, garantindo que apenas os serviços necessários sejam escalados, em vez de todo o sistema.
Resiliência: Como os microsserviços são independentes, uma falha em um serviço não afeta necessariamente o funcionamento de todo o sistema. Isso permite uma maior resiliência, já que o sistema pode continuar a funcionar mesmo que alguns serviços estejam com problemas.
Implantação contínua: Os microsserviços são frequentemente implantados por meio de práticas de integração contínua e implantação contínua (CI/CD), onde as alterações em um serviço podem ser implantadas rapidamente sem afetar o funcionamento dos outros serviços.
Comunicação entre serviços: A comunicação entre os microsserviços geralmente é feita por meio de chamadas de API, seja síncrona (como REST ou gRPC) ou assíncrona (usando mensageria). Isso permite que os serviços se comuniquem e compartilhem informações de forma controlada.
Escopo delimitado: Cada microsserviço tem um escopo delimitado, o que significa que é responsável por uma única funcionalidade ou conjunto de recursos. Isso facilita a compreensão do sistema como um todo e o desenvolvimento de equipes especializadas em cada serviço.
Governança e gerenciamento: A gestão e governança dos microsserviços podem envolver a coordenação de implantações, monitoramento de desempenho, tratamento de erros, segurança, entre outros aspectos. Ferramentas específicas e práticas de DevOps podem ser adotadas para garantir a efetividade e estabilidade do ambiente de microsserviços.
Os microsserviços são amplamente adotados em ambientes modernos de desenvolvimento de software, permitindo a construção de sistemas escaláveis, resilientes e flexíveis. No entanto, eles também trazem desafios adicionais em termos de complexidade, coordenação entre serviços e gerenciamento da infraestrutura. A decisão de adotar a arquitetura de microsserviços deve ser avaliada com base nos requisitos do projeto, capacidade da equipe e necessidades específicas do sistema em questão.
A mensageria, no contexto da computação, refere-se ao uso de sistemas e tecnologias para permitir a comunicação assíncrona entre diferentes componentes de um sistema distribuído. É uma abordagem que permite que os componentes se comuniquem de forma eficiente, mesmo quando estão em diferentes plataformas, linguagens de programação ou locais físicos.
Aqui estão alguns conceitos e componentes relacionados à mensageria:
Mensagem: É uma unidade de informação que é transmitida entre os componentes de um sistema distribuído. Uma mensagem geralmente contém dados estruturados que são enviados de um remetente para um ou mais destinatários.
Fila de mensagens: É uma estrutura de armazenamento que mantém as mensagens em ordem de chegada. Os remetentes colocam as mensagens na fila e os destinatários as retiram quando estão prontos para processá-las. Isso permite o processamento assíncrono e evita a perda de mensagens caso o destinatário não esteja disponível imediatamente.
Produtor: É o componente que envia ou publica as mensagens na fila de mensagens. Ele é responsável por criar e enviar as mensagens para que outros componentes possam consumi-las.
Consumidor: É o componente que recebe ou consome as mensagens da fila. Ele é responsável por retirar as mensagens da fila e processá-las de acordo com a lógica de negócio do sistema.
Broker de mensagens: É um componente intermediário responsável por receber as mensagens dos produtores e entregá-las aos consumidores apropriados. Ele gerencia a fila de mensagens, garante a entrega correta e mantém a ordem das mensagens, se necessário.
Tópico: É um mecanismo de mensageria que permite que as mensagens sejam enviadas a múltiplos consumidores interessados em um determinado assunto. Os consumidores que estão inscritos em um tópico específico receberão todas as mensagens relacionadas a esse tópico.
Protocolos de mensageria: Existem vários protocolos e tecnologias utilizados na implementação de sistemas de mensageria, como AMQP (Advanced Message Queuing Protocol), MQTT (Message Queuing Telemetry Transport), Apache Kafka, RabbitMQ e muitos outros.
A mensageria é amplamente utilizada em sistemas distribuídos, microservices, arquiteturas orientadas a eventos e integração de sistemas. Ela permite a comunicação confiável, escalável e assíncrona entre componentes, facilitando a construção de sistemas mais resilientes, flexíveis e distribuídos.
Logging, em termos de programação, refere-se ao processo de registrar informações relevantes sobre a execução de um programa ou sistema em um arquivo ou outro meio de armazenamento. O logging é uma prática essencial para o monitoramento, solução de problemas e análise de desempenho de software.
Aqui estão alguns pontos importantes relacionados ao logging:
Registro de eventos: O logging é usado para registrar eventos significativos durante a execução de um programa, como erros, exceções, avisos, informações de depuração e outros eventos relevantes. Esses registros podem ser úteis para rastrear problemas, identificar padrões de comportamento e entender o fluxo de execução do software.
Níveis de log: Os sistemas de logging geralmente suportam vários níveis de log, como DEBUG, INFO, WARNING, ERROR e FATAL. Cada nível possui um propósito específico e ajuda a filtrar a quantidade de informações registradas, permitindo que os desenvolvedores concentrem-se nas áreas relevantes durante a análise de logs.
Formato de logs: Os logs podem ser registrados em diferentes formatos, como texto simples, JSON, XML ou outros formatos estruturados. O formato escolhido deve ser adequado para a análise e processamento posterior dos registros.
Bibliotecas e frameworks de logging: Existem várias bibliotecas e frameworks disponíveis para implementar o logging em diferentes linguagens de programação. Exemplos populares incluem log4j/log4net para Java/.NET, logging para Python, e ILogger para .NET Core.
Armazenamento de logs: Os registros podem ser armazenados em arquivos de log, bancos de dados ou outras fontes de armazenamento. A escolha depende das necessidades do projeto e dos requisitos de segurança, escalabilidade e análise.
Análise de logs: Os logs são uma valiosa fonte de informações para análise e monitoramento de sistemas. Ferramentas de análise de logs podem ser usadas para pesquisar, filtrar e extrair insights a partir dos registros, ajudando a identificar problemas, tendências de desempenho e padrões de comportamento.
É importante implementar o logging de forma adequada, definindo o nível de log apropriado, registrando informações relevantes e úteis, e garantindo que os logs sejam armazenados e analisados de forma eficiente. Logging bem implementado pode ajudar no desenvolvimento, manutenção e operação de sistemas, fornecendo informações valiosas para solução de problemas e melhoria contínua.
A programação é um campo amplo e em constante evolução, e há uma variedade de livros disponíveis que podem ajudar a aprimorar suas habilidades e conhecimentos. Aqui estão algumas recomendações de livros populares sobre programação:
“Clean Code: A Handbook of Agile Software Craftsmanship” – Robert C. Martin: Este livro aborda os princípios e práticas para escrever código limpo e de qualidade, promovendo uma abordagem profissional no desenvolvimento de software.
“The Pragmatic Programmer: Your Journey to Mastery” – Andrew Hunt e David Thomas: Este livro explora várias técnicas e abordagens práticas para se tornar um programador mais eficiente e eficaz, abordando temas como gerenciamento de projetos, ferramentas e boas práticas de programação.
“Design Patterns: Elements of Reusable Object-Oriented Software” – Erich Gamma, Richard Helm, Ralph Johnson e John Vlissides: Este clássico livro descreve 23 padrões de design de software que ajudam a resolver problemas comuns no desenvolvimento de aplicativos.
“Introduction to the Theory of Computation” – Michael Sipser: Este livro é uma introdução à teoria da computação, abrangendo tópicos como autômatos finitos, gramáticas formais, máquinas de Turing e complexidade computacional.
“Refactoring: Improving the Design of Existing Code” – Martin Fowler: Este livro explora técnicas de refatoração, que envolvem reestruturar o código existente para melhorar sua legibilidade, manutenção e desempenho.
“Cracking the Coding Interview: 189 Programming Questions and Solutions” – Gayle Laakmann McDowell: Este livro é uma referência popular para entrevistas de emprego em empresas de tecnologia, fornecendo uma ampla variedade de perguntas e soluções de programação.
“Programming Pearls” – Jon Bentley: Este livro apresenta uma coleção de problemas de programação do mundo real, abordando técnicas eficientes para resolvê-los e fornecendo insights valiosos sobre o processo de desenvolvimento de software.
“The Mythical Man-Month: Essays on Software Engineering” – Frederick P. Brooks Jr.: Neste livro clássico, o autor explora os desafios e as complexidades da engenharia de software, discutindo temas como gerenciamento de projetos, estimativas e problemas de escalabilidade.
“Effective Java” – Joshua Bloch: Este livro aborda as melhores práticas e padrões de programação para a linguagem Java, fornecendo conselhos úteis para escrever código Java eficiente, seguro e de alta qualidade.
“Head First Design Patterns” – Eric Freeman, Elisabeth Robson, Bert Bates e Kathy Sierra: Este livro apresenta os princípios e padrões de design de software de uma forma envolvente e fácil de entender, usando uma abordagem visual e interativa.
Esses são apenas alguns exemplos de livros sobre programação que podem ajudar no aprimoramento das suas habilidades. É importante selecionar os livros com base nos seus interesses, objetivos e área específica de programação que você deseja explorar.
O home office, também conhecido como trabalho remoto ou teletrabalho, é uma prática em que os profissionais realizam suas atividades de trabalho em suas residências ou em locais fora do escritório tradicional. Com os avanços da tecnologia e a conectividade proporcionada pela internet, o home office tem se tornado cada vez mais comum em diversas áreas de trabalho.
Existem várias razões pelas quais o home office tem ganhado popularidade:
Flexibilidade: Trabalhar em casa permite maior flexibilidade no gerenciamento do tempo. Os profissionais podem definir seus próprios horários de trabalho, adaptando-se às suas necessidades pessoais e familiares.
Economia de tempo e deslocamento: Ao trabalhar em casa, os profissionais economizam tempo e recursos que seriam gastos em deslocamento para o escritório. Isso reduz o estresse relacionado ao trânsito e proporciona mais tempo para se dedicar às atividades profissionais e pessoais.
Produtividade: Algumas pesquisas mostram que o trabalho remoto pode aumentar a produtividade. Sem distrações do ambiente do escritório e com maior autonomia, os profissionais têm a oportunidade de se concentrar mais nas tarefas e alcançar melhores resultados.
Conciliação trabalho-vida pessoal: O home office permite uma melhor conciliação entre trabalho e vida pessoal. Os profissionais têm mais tempo para se dedicar à família, cuidar da casa e participar de atividades pessoais, o que contribui para o bem-estar e a qualidade de vida.
Redução de custos: Tanto para os profissionais quanto para as empresas, o home office pode trazer economia de custos significativa. Os profissionais economizam em despesas de transporte, alimentação fora de casa e vestuário de escritório, enquanto as empresas podem reduzir os custos relacionados a espaço físico e infraestrutura do escritório.
No entanto, o home office também apresenta desafios. É necessário estabelecer rotinas, disciplina e organização para garantir a produtividade e separar claramente o tempo de trabalho do tempo pessoal. Além disso, a comunicação efetiva com a equipe e a manutenção do engajamento podem exigir esforços adicionais para superar a distância física.
Com a evolução da tecnologia e as mudanças nas formas de trabalho, muitas empresas têm adotado o home office como uma opção viável e flexível.